
The subjects loosely grouped under the heading “eDiscovery” come and go or, rather, they fill the airwaves for a while and then become absorbed into the mainstream to be replaced by the next hot topic.
There was a time when the conference platforms were full of “Big Data”. Big data had a fairly precise definition, but it was also used loosely to refer to the ever-increasing volumes of data of all types and the massive increase in processing and distribution power which accompanied them. Fairly quickly, that became just “data”, and we moved on to talking about the next big topic which, as it happens, was privacy, followed by security. The everyday ubiquity of data, its translation into usable information, its aggregation, and the potential for misuse whether for criminal purposes or political ones, became all-consuming threats for organisations of all sizes, and for individuals. All those little scraps of data which we push out unthinkingly could be captured, aggregated and used for purposes good or bad, often for purposes unthought of by the creator. Photographs and video could be created by anyone, and most of it was geotagged by default. Increasingly sophisticated intelligent software could pull threads together, make matches, and draw conclusions.
The war in Ukraine has accelerated the use of this kind of data, both for combat purposes and for the collection of evidence which will be used in due course for the purposes of war crimes investigations. I am always keen on stories from the news which help illuminate eDiscovery issues.
The war has given us many examples of photographs and videos being used not merely to capture an event but to identify the people in the picture, and the time and place of the filming. Ukraine has, for example, been using facial recognition software to identify the bodies of dead Russian soldiers by matching them with pictures found on social media, with hacked military databases, and have done the same for perpetrators of violence against civilians. Google Maps Street View pictures, and other publicly-available sources, are used to pin a picture or video to a place.
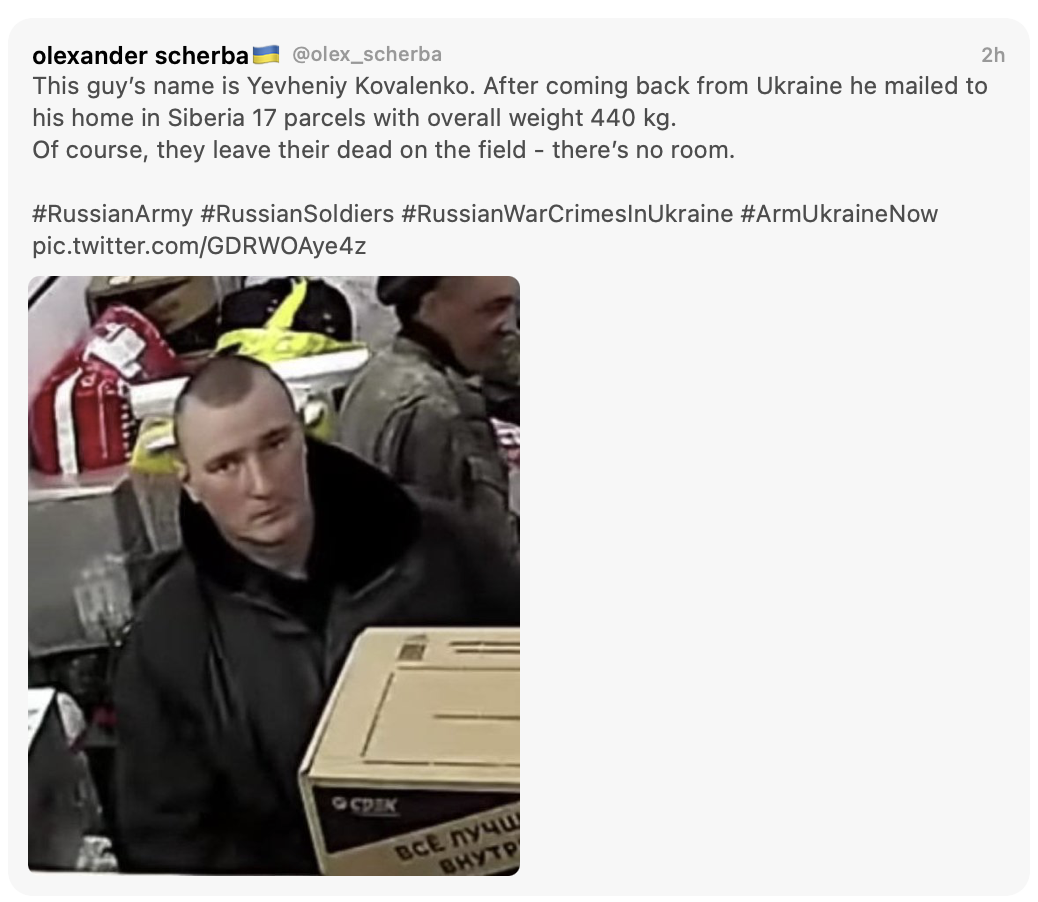
One of the best examples of personal identification is the video frame which shows Russian soldiers packing up stolen property to send home. Many of them have been identified.
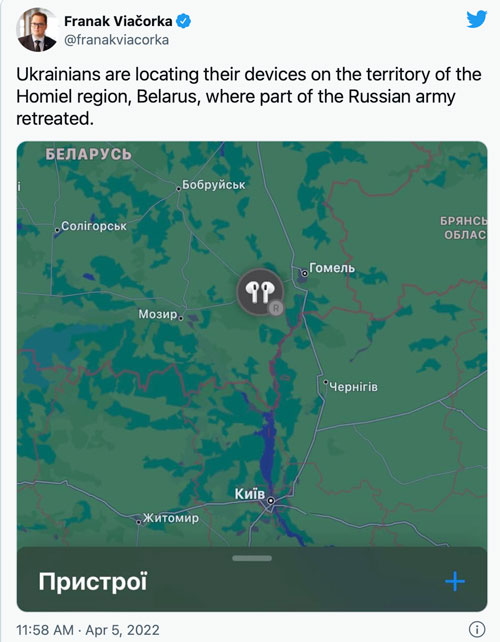
In addition, Ukrainians have been using device-tracking apps such as Apple’s Find My Phone to see where their connected devices have ended up.
An older point resurfaced. Those of us who have promoted the idea that data must be protected have always emphasised the risk inherent in lists of names, even before computerisation. I see daily Twitter posts about people taken to Auschwitz. Everyone on those trains was there because their names were on lists – they were Jews, or socialists, or Roma, or had some other characteristic which condemned them. Compliant officials in occupied countries were keen to help compile those lists.
Here’s a tweet about similar lists used by the Russians in Ukraine.

__________
The inventiveness shown in Ukraine has application in less dramatic fields. We will, I suspect, see greater use of technology in crime detection as a result of lessons learnt in the war. There is more to this than simply pointing clever devices and software at people at places, people and events. Back in 2018 I wrote about using the brain to analyse pictures rather than just relying on technology – see From Prague to Piccadilly Circus: drawing conclusions about a photograph without the help of metadata. That article gives an example from Bellingcat, now acknowledged as the star of open source and social media investigation.
We can bring this back to more mundane discoveries from everyday social media. Usually, this involves evidence on, say, Facebook which contradicts evidence given in court proceedings. One of the early examples of this was in 2015, when a claim against Cirencester Friendly Society for sickness insurance was undermined by Facebook entries showing the claimant’s involvement in physically demanding leisure activities. I wrote about that and other examples in a 2017 article called Non-conventional data sources and the crossover between litigation disclosure and privacy. One of the points which arose then was whether people knew if they had location services switched on, and what the implications were of that in terms of the crossover between the resulting data, disclosure/discovery, and privacy.
In another article, in 2014, when the world was young and relatively innocent, I wrote (among other things), of so-called celebs who found their “nude selfies” spattered all over the media. I suggested that the geodata which showed where the pictures were taken was potentially more awkward than the pictures themselves.
The Ukraine war has given us examples of rather more terminal consequences – of soldiers posting pictures which betray precisely where they are. The embarrassment of a nude celeb is trivial compared with the rain of shells or rockets which might be brought down on that location. There are wider consequences too, if (as is happening) Ukraine has access to data which, when cross-referred with the picture data, reveals information about troop dispositions from which military intentions may be inferred.
What of all this is relevant to the obligation to disclose documents in litigation? As a potential party or witness, you may not fear a rain of rockets, but you might not want to disclose where you were at any given time. If you did capture that information, whether you knew it or not, you cannot just delete it if the rules in your jurisdiction (they vary a bit) have by then imposed a duty to preserve potentially disclosable data.
If you are the lawyer in a case where phone data – calls, messages, pictures, location history – may be relevant, you may have duties to ask about it, both of your own client and of the opponents. Quite apart from the formal disclosure duties, that data may prove a point your client needs to make, or may undermine something said by the other side.
I say “may have duties” because there are many cases where it is obvious that pursuit of phone data is irrelevant and disproportionate. You must at least ask yourself that question.
And if you are just you and me, with no thought of being embroiled in litigation of any kind, it is still worth asking yourself what data you are creating and keeping, and what use others may make of it either on its own or (and this is the real issue) when aggregated with the mass of data collected about you from all sources. To give an example which turned up at home last week, what about that smart meter which energy suppliers keep urging you to have – who gets access to that data who might be able to add it to other information? The answer is not limited to the energy supplier itself, because they may be hacked and the data sold to others.
One might overdo this reserve – as with litigation one’s attitude must be proportionate, and one must take account of benefits which may follow from sharing data. Your worst risk may be identity theft or credit card fraud rather than a hail of rockets or an appearance before a war crimes tribunal but it is, at the least, worth thinking about it before handing over your data.

