
An article in the Law Society Gazette is headed High Court backs predictive coding in first contested case. It is a report on the judgment which I mentioned briefly last week in which clients of BLP won the right to use predictive coding for the purposes of giving disclosure.
Unlike Pyrrho Investments v MWB Property (on which I have written and spoken exhaustively, indeed exhaustingly) this application was contested, with the other side presumably arguing either for manual page turning, or for the use of some different technology or, at least, against the use of predictive coding.
There is as yet not much to see in terms of the recent order, with neither the Law Society Gazette article nor BLP’s own article adding much to our knowledge.
I am more interested in the anonymous comment which appeared below the article:
As lawyers we like to see the documents, read them and then decide their relevance.
Before we start, let’s be clear about two things:
- In urging the use of technology to aid disclosure, I am NOT suggesting that you disclose documents which you have not read. Opponents of technology affect to translate the suggestion as meaning that you chuck all the data into a “black box” and throw the output at the other side. That is emphatically NOT what is meant. I accept too that wide reading is desirable; its fence is called proportionality.
- Most litigation does not involve very large volumes of documents nor high enough values (whether measured in money or not) to warrant the use of technology like predictive coding; the commenter, however, chose to make the comment on an article about predictive coding, and it must be assumed that the comment applies to those cases for which this technology is at least arguably appropriate.
My tweeted observation was:
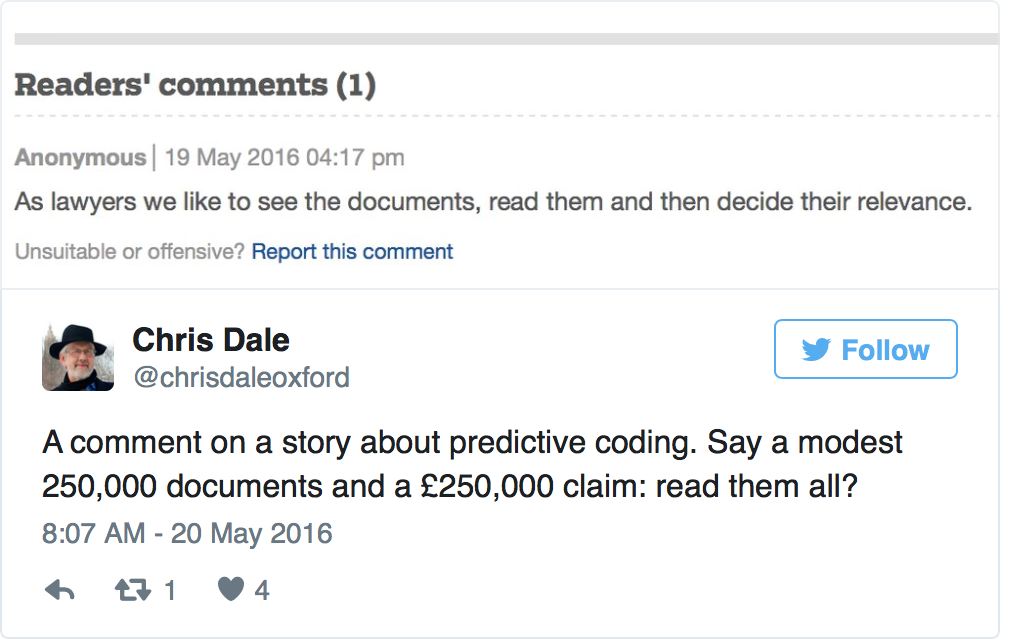
A rather one-sided Twitter debate followed – one-sided in that no one turned out to support the idea that every document could be read in a case of any size, however much this may appeal to a conscientious lawyer.
It is not necessarily right to preserve spur-of-the-moment tweets in the amber of a blog post, so I will summarise them:
It is easy to underestimate how many documents can be created in an apparently simple transaction, especially if it extends over several years. Many would be duplicates and if technology is used only to weed the duplicates and group the near-duplicates together, then that is a major saving.
The conscientious solicitor wanting to read everything (in a big case) has multiple tiers of questions: how many documents would be formally disclosable on the broadest interpretation of the lawyer’s duty and (a narrower question) how many of those will have any evidential value? All cases come down to very few issues and very few documents. More documents does not necessarily mean better justice and the English disclosure rules are driving parties to arbitration – “we need to get a grip” said one barrister.
I referred to the recent Court of Appeal case in which the court “could not even discern from the pleadings what the issues were”. A closer focus on the issues would lead to narrower pleadings which in turn leads to less disclosure and a quicker route to the handful of points and documents which matter. As it happens, that same point came up in the panel which I moderated last week on predictive coding. It was raised by US Magistrate Judge David Waxse as an issue in US proceedings; one way of reducing discovery, he said, was to be clear what issues it concerned.
[The Court of Appeal case was The Prudential Assurance Company Limited -v- Commissioners for Her Majesty’s Revenue and Customs. Gordon Exall has written about it here].
I digress. The tweets above can stand substitute for most of what I would say in answer to the comment on the assumption (I stress again) that the comment was intended to relate to the kind of cases to which the article referred.
Reducing further observations to the barest minimum:
- As I have said above, no one is suggesting that you disclose documents you have not read (though some may choose to do so). The primary value of predictive coding lies in weeding out the obvious dross and prioritising the rest. You can then read the ones which are presumed to be the most relevant in order of relevance, stopping when the ratio of time spent to value returned makes it disproportionate to continue.
- If your starting point was a million documents, you may still have to read thousands, even tens of thousands of them. If you carry on reading patiently through irrelevant documents then, whether or not your client approves of your doing so, the court is unlikely to award you the costs of all that reading. Indeed, you are unlikely to be able to meet the court’s timetable for giving disclosure.
- It is also unlikely that that you will miss the fabled “smoking gun”, or anything else of value, or anything significant which ought to be disclosed under a definition of “disclosable” which expressly requires proportionality and a “reasonable search” and which has case law authority against looking under every stone.
- Predictive coding technology offers ample opportunity to check your work, by sampling both the documents which are presumed relevant and those provisionally deemed irrelevant.
I can quite understand those who sympathised with the Gazette comment as a statement of the ideal. I certainly don’t criticise the conscientiousness of lawyers who would like to read everything. We are forced into a practical, pragmatic approach which tempers the ideal with the brute reality that we cannot read it all. The technology is not a substitute for the exercise of a lawyer’s judgement, but an aid – an aid to the exercise of discrimination between the relevant and the irrelevant, and an aid to compliance with the rules, which requires the insertion of proportionality into the calculation of how much must be done.
I really do not care for their own sakes if the lawyers are working inefficiently, and it is not my business to suggest that some have practices which must inevitably lead to doom. I am, however, extremely interested in preserving disclosure as a source of evidence before the rule-makers decide to dispense with it and before the clients turn their backs on litigation. I am interested too in London’s role as a centre for dispute resolution, and not just for the very rich.
The rules, the cooperation required by the rules, and the discretion of the court, give ample opportunity to cut down disclosable information properly and thereby to reduce the time and cost of litigation. Technology helps that process. If we don’t use the rules and the technology for that purpose then litigation must inevitably decline, and at all levels.
I know nothing of the author of the comment. It may well be that he or she has a practice which allows the luxury of reading every document and making a viable business out of doing so. The part of the comment which I object to is its opening “As lawyers we like..”, purporting to tar the whole profession with this approach.
There are many who have appreciated that we cannot go on like this and have, at the least, taken the first step and seen some of this technology. If, having done so, you still reject it for your own use, then at least you will be able to engage in the conversation when your opponent suggests its use.

