
Use Abbyy FineReader to OCR .tiff images and save to .pdf and then use Adobe Acrobat 8 Professional to save in JBIG2 format. It sounds a long route but the results are smaller and better than anything else I have found.
The client’s request seemed an obvious one – he wanted his .TIFF images turned into the smallest-sized Acrobat .PDFs with the best-quality OCR text saved within them. Having it actually stated as a requirement made me do some tests whose outcome was interesting.
For those who do not know, Acrobat .PDFs can be plain images or can have their text stored in them. Some litigation systems can make use of the stored text for searching purposes – Caselogistix among them. It is fairly obvious why you want the best-quality OCR, and no less clear why you want the smallest possible images – you pay for storage by the gigabyte, and the smaller the image the faster it comes up over the Web.
The conventional route to the double objective when starting from an existing file is to use a print driver which sends the original to a “printer” which converts the output into a .PDF. This can be done in bulk with some applications.
Adobe Acrobat 8 Professional allows you to fine-tune the output. The obvious choice is the save-for-web option which makes the first page of a document appear without waiting for the whole document to load. In addition, you can reduce the output quality – this cuts the size down but necessarily results in lower visual quality.
Litigation support people are a co-operative lot on the whole and are good at sharing ideas and discoveries, particularly those which help everyone. It does not mean that you give away the things which give you or your clients a competitive advantage over others, but it is often the case that helping the opposition helps you as well. If my clients are given small .PDFs with high-quality OCR by their opponents, everyone benefits.
Whole books and training courses are devoted to the functions and features of Acrobat 8 Pro. I played with it for a while and found an output format which was new to me called JBIG2. Contrary to what its name implies, JBIG2 reduces the output size, in some cases by nearly 50%, and is independent of the quality settings. I could see no reduction in visible quality, and test samples worked properly on the clients’ hosted system.
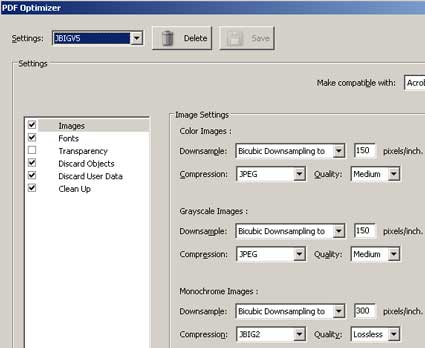
The output settings in Acrobat 8 Professional
So much for the size part of the client’s request. What about OCR? Acrobat 8 Pro has bulk OCR built into it, and the obvious course was to combine this with save-for-web and JBIG to do the whole exercise in one batch process.
It would be easy to take it for granted that Adobe’s OCR function is at least as good as anyone else’s. I was not, however, particularly impressed with the results of a test on a .TIFF image chosen deliberately for some difficult text, including off-white print on a grey background.
My usual OCR package is Abbyy FineReader which handles .TIFFs and .PDFs wth equal facility and to a very high quality. It had no difficulty with the off-white print. I usually use it to make plain text for dropping into database fields, but Abbyy FineReader also has the option to produce .PDF images as the output of the OCR exercise. These, however are saved in the ordinary .PDF format, with no option to save as JBIG2 nor as save-for-web.
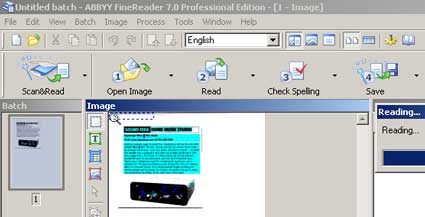
Abbyy FineReader OCRs to PDF
Two processes then. Use Abbyy to bulk-OCR the .TIFFs and save the output as ordinary .PDFs. Then use Acrobat 8 Professional to resave them as save-for-web PDFs in JBIG format. The OCR is unaffected by any compression option since it is the original .TIFFs which are being OCR’d. It takes much longer to resave the .PDFs in JBIG2 format than in the default .PDF format, presumably because of the compression which is taking place. In the context of the several days it took to do the OCR, however (Abbyy is not quick), an hour or two to resave as JBIG2 adds little to the exercise and is well worth it for a near 50% space saving.
There is one caveat as to the Abbyy FineReader part of this which did not appear until later. A process which OCRs a .TIFF image and saves the output as a .PDF is actually disassembling the document and putting it back together. My tests did not show any obvious shortcomings in Abbyy’s output from this. Working later with a different set of documents, I found that some logos and certain pictures had not come out in a form which accurately reflected their origin. Abbyy had tried to be too clever; where Acrobat spots an image and leaves it alone, Abbyy has a go, not always successfully, and then uses its output to rebuild the page. This did not affect the documents in my sample because the document set was pretty well all text.
There is a simple trade here. The costs-savings in storage, the higher quality OCR and the faster-loading files are all worth having. The resulting .PDF must, however, be the same in appearance as the document from which it came. If the document set includes a high proportion of logos which Abbyy fouls up, then this route may not be the best. If you decide against Abbyy, then using Acrobat to save the .PDF as JBIG2 is still well worth it for size reasons.
So – a happy client, and something learned. If you want help with any similar process, or with any aspect of handling documents data for litigation, please contact me.

